一、Redis 是什么
**
Redis,全称是 Remote Dictionary Server ,是一个开源的内存数据结构存储系统。它以其卓越的性能和丰富的功能,在现代软件开发中占据了重要地位,可作为数据库、缓存和消息中间件使用 。
Redis 的数据存储在内存中,这使得它的读写速度极快,能轻松应对高并发场景。举个例子,在一个电商大促活动中,大量用户同时涌入商品详情页,如果数据从传统磁盘数据库读取,响应速度会很慢,用户体验极差。而使用 Redis 作为缓存,将商品信息提前存储在内存中,用户请求时可以直接从 Redis 快速获取数据,实现秒级甚至毫秒级的响应,大大提升了系统的吞吐量和用户体验。
Redis 支持多种数据结构,如字符串、哈希、列表、集合和有序集合等。不同的数据结构适用于不同的业务场景,为开发者提供了极大的灵活性。例如,在社交平台中,使用哈希结构可以方便地存储用户的各种信息,如昵称、头像、简介等;使用有序集合可以轻松实现热门话题排行榜,根据话题的热度(如参与讨论的人数、点赞数等)进行排序展示。
二、为什么选择 Redis
(一)性能优势
Redis 的性能优势主要体现在其惊人的读写速度上。官方数据显示,Redis 单实例的读速度可达 110000 次 / 秒 ,写速度可达 81000 次 / 秒。在一些对读写速度要求极高的场景,如秒杀活动,Redis 的高性能优势就能够充分体现。在秒杀开始前,将商品库存等关键数据存储在 Redis 中,当大量用户同时发起抢购请求时,Redis 可以快速响应,实现对库存的原子性操作,保证数据的准确性和一致性。相比传统的数据库,Redis 可以轻松应对高并发,避免因读写压力过大导致系统崩溃。
(二)丰富的数据结构
Redis 支持多种数据结构,每种数据结构都有其独特的应用场景:
- 字符串(String):这是 Redis 最基本的数据结构,可用于缓存、计数器等场景。比如在统计网站访问量时,就可以使用字符串类型结合 INCR 命令,每次有用户访问时,对相应的键进行自增操作,方便快捷地实现计数功能。
- 哈希(Hash):适合存储对象,以电商系统中的商品信息存储为例,我们可以将商品 ID 作为键,商品的名称、价格、库存等属性作为哈希的字段,方便对商品信息进行管理和更新。
- 列表(List):可以实现消息队列和任务队列。在订单处理系统中,用户提交订单后,将订单信息使用 RPUSH 命令添加到列表右侧,后台订单处理程序使用 LPOP 命令从列表左侧获取消息,实现消息的先进先出。
- 集合(Set):具有去重和支持集合运算的特点,常用于统计网站独立访客数量,将每个访客 ID 添加到集合中,利用其唯一性实现去重;在社交网络中,通过集合的交集操作可以找出两个用户的共同好友 。
- 有序集合(Sorted Set):每个元素关联一个分数,根据分数排序,常用于排行榜场景。游戏中可以根据玩家得分排名,将玩家 ID 作为元素,得分作为分数存储在有序集合中,通过 ZRANGE 命令获取排名靠前的玩家。
(三)应用场景广泛
Redis 的应用场景极为广泛,以下是一些常见场景:
- 缓存:这是 Redis 最常用的场景之一。在 Web 应用中,将频繁访问的数据如用户信息、商品详情等缓存到 Redis 中,能显著减少数据库的压力,提高系统响应速度。以新闻网站为例,用户访问新闻详情页时,先从 Redis 中查找新闻内容,如果存在则直接返回,不存在再从数据库获取并存储到 Redis 中。
- 消息队列:Redis 的发布 / 订阅模式和列表数据结构可实现轻量级消息队列功能。比如在用户注册成功后发送欢迎邮件、用户下单后生成订单等场景中,就可以利用 Redis 消息队列实现异步处理,提高系统的并发能力和处理效率 。
- 分布式锁:在分布式系统中,为保证多个服务或实例对共享资源的访问不冲突,可使用 Redis 实现分布式锁。例如在电商秒杀活动中,通过 Redis 分布式锁防止超卖,在扣减库存前先获取锁,确保只有一个请求能操作库存 。
三、Redis 的使用场景详解
(一)缓存
在当今互联网应用中,数据量呈爆炸式增长,数据库面临着巨大的压力。Redis 作为缓存,可以将频繁访问的数据存储在内存中,大大减少数据库的访问次数,从而降低数据库压力。当用户请求数据时,系统首先检查 Redis 缓存中是否存在该数据。如果存在,直接从 Redis 中获取数据并返回给用户,这个过程只需要几毫秒甚至更短的时间,极大地提高了系统的响应速度。以电商平台为例,商品的详情信息、用户的购物车数据等都是频繁访问的数据,将这些数据缓存到 Redis 中,可以显著提升用户购物的流畅性和体验感。
(二)计数器
在很多应用场景中,计数器是必不可少的功能,如统计网站的访问量、文章的点赞数、视频的播放量等。Redis 的原子操作特性使得它在实现计数器功能时表现出色。以统计网站访问量为例,每次有用户访问网站时,使用 Redis 的 INCR 命令对表示网站访问量的键进行自增操作。由于 INCR 命令是原子性的,即使在高并发情况下,多个用户同时访问,也能保证数据的准确性和一致性,不会出现计数错误的情况 。
(三)消息队列
在分布式系统中,消息队列是实现异步任务处理和系统解耦的重要组件。Redis 可以通过发布 / 订阅模式和列表数据结构来实现简单的消息队列。以电商系统中的订单处理为例,用户下单后,订单信息通过 RPUSH 命令被添加到 Redis 列表中,后台的订单处理程序则使用 LPOP 命令从列表中获取订单信息并进行处理。这样,订单处理和用户下单操作就实现了异步化,即使订单处理程序出现故障,也不会影响用户下单,同时也降低了系统各模块之间的耦合度 。
(四)分布式锁
在分布式系统中,多个服务实例可能同时访问共享资源,为了避免数据不一致和竞态条件,需要使用分布式锁。Redis 实现分布式锁的基本原理是利用 SET 命令的 NX(Set if Not eXists)选项,当键不存在时才能设置成功,以此来保证同一时间只有一个客户端能获取到锁。在电商秒杀活动中,为了防止商品超卖,在扣减库存前,先使用 Redis 获取分布式锁。只有获取到锁的请求才能执行扣减库存操作,操作完成后释放锁,其他请求在获取锁失败后等待或重试,从而确保了库存数据的一致性和准确性 。
四、Redis 的安装与配置
(一)安装步骤
- Linux 系统:在 Linux 系统中,安装 Redis 有多种方式,这里以 Ubuntu 系统为例,介绍通过包管理器安装的方法。首先,打开终端,使用以下命令更新软件包列表:
接着,执行安装命令:
sudo apt install redis-server
安装完成后,可以使用以下命令启动 Redis 服务:
sudo systemctl start redis-server
为了确保 Redis 服务在系统启动时自动运行,可以使用以下命令设置开机自启:
sudo systemctl enable redis-server
如果需要停止或重启 Redis 服务,相应的命令分别是:
sudo systemctl stop redis-server # 停止服务sudo systemctl restart redis-server # 重启服务
- Windows 系统:Windows 系统下安装 Redis 可以从微软维护的 Redis for Windows 版本进行下载。首先,前往相关下载渠道,下载 Redis for Windows 的最新版本,然后解压下载的 ZIP 文件到你想安装的目录。
解压完成后,打开解压目录中的redis-server.exe启动 Redis 服务。若要启动客户端,可以打开另一个命令提示符窗口,使用redis-cli.exe与 Redis 进行交互。例如,在命令提示符中输入redis-server.exe启动服务端,再打开新的命令提示符窗口输入redis-cli.exe启动客户端。
另外,如果您正在使用 Windows 10 或更高版本,还可以使用 WSL(Windows Subsystem for Linux)来安装 Redis。具体步骤为:首先,打开 PowerShell 并以管理员身份运行以下命令启用 WSL:
这将安装默认的 Ubuntu 发行版。安装完成后,启动 Ubuntu 终端并运行以下命令安装 Redis:
sudo apt updatesudo apt install redis-server
安装完成后,使用以下命令启动 Redis 服务:
sudo service redis-server start
- Mac 系统:在 Mac 系统中,使用 Homebrew 安装 Redis 非常便捷。在使用 Homebrew 安装 Redis 之前,首先要确保你的 Mac 系统已经安装了 Homebrew。若尚未安装,可在 Mac 的终端中执行以下命令进行安装:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
这条命令会从 Homebrew 的官方安装脚本地址下载并执行安装程序,安装过程中可能需要输入系统密码进行确认。安装完成后,在终端中执行安装 Redis 的命令:
Homebrew 会自动从其软件仓库中下载 Redis 及其所有依赖项,并进行安装。安装完成后,Homebrew 会自动为 Redis 配置好相关的环境变量,用户无需手动进行设置。
(二)基本配置
Redis 的配置文件通常位于/etc/redis/redis.conf(Linux 系统)或/usr/local/etc/redis/redis.conf(Mac 系统),Windows 系统中解压目录下的redis.windows.conf也可进行配置。以下是一些常用参数的含义和配置方法:
- bind:指定 Redis 服务器绑定的 IP 地址。默认值通常是127.0.0.1,表示只允许本地访问。如果希望 Redis 可以被其他机器访问,可将其设置为服务器的实际 IP 地址,或者设置为0.0.0.0允许所有 IP 访问,但这样会存在一定安全风险,建议结合requirepass配置密码使用。例如,若服务器的 IP 地址是192.168.1.100,可将bind配置为192.168.1.100 。
- port:设置 Redis 服务器监听的端口,默认值为6379。如果该端口被其他程序占用,可修改此端口号。比如,将其修改为6380 ,在配置文件中找到port 6379 ,将其改为port 6380 。
- requirepass:设置 Redis 访问密码。在未设置密码的情况下,任何可以访问 Redis 服务器的客户端都可以执行命令,存在安全隐患。设置密码后,客户端在连接 Redis 时需要通过AUTH命令进行密码验证。例如,设置密码为mypassword ,在配置文件中添加requirepass mypassword ,客户端连接时,先输入redis-cli ,然后使用AUTH mypassword进行密码验证。
- daemonize:指定 Redis 是否以守护进程方式运行。默认值为no ,表示不以守护进程方式运行;若设置为yes ,Redis 将在后台运行。在生产环境中,通常将其设置为yes ,修改配置文件中的daemonize no 为daemonize yes 。
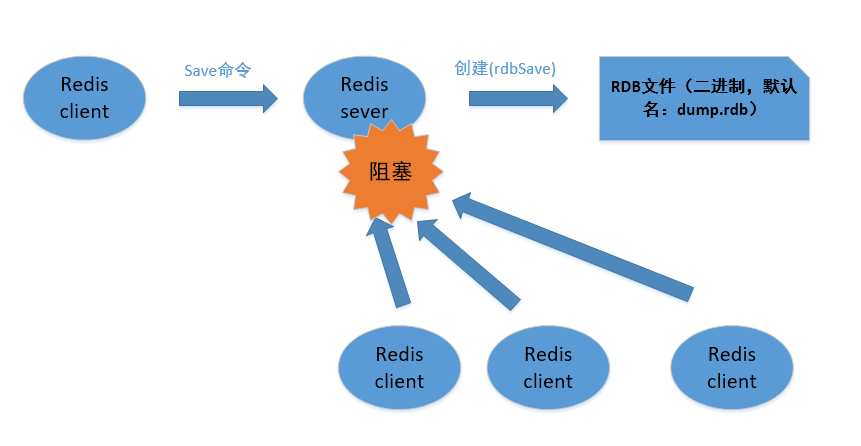
- save:用于配置 Redis 的 RDB 持久化策略。例如,默认配置save 900 1表示在 900 秒(15 分钟)内,如果至少有 1 个键发生变化,就会触发 RDB 持久化操作,将内存中的数据快照保存到磁盘上。可根据业务需求调整这些参数,如save 300 10表示 300 秒(5 分钟)内至少有 10 个键发生变化时进行持久化 。
五、Redis 核心操作与实践
(一)常用命令
Redis 提供了丰富的命令,以下是一些常用命令及其示例:
- SET:用于设置键值对。例如,SET name "John",将键name的值设置为John。
- GET:用于获取指定键的值。如GET name,将返回John。
- INCR:对存储在指定键中的数字值执行原子加 1 操作。例如,SET count 10 ,然后INCR count ,此时count的值变为 11。
- HSET:用于在哈希表中设置字段和值。例如,HSET user:1 name "Alice" ,表示为用户 1 设置姓名为 Alice 。
- HGET:用于获取哈希表中指定字段的值。如HGET user:1 name ,将返回Alice 。
- HGETALL:获取哈希表中的所有字段和值。HGETALL user:1 ,会返回用户 1 的所有信息。
- LPUSH:从列表的左侧插入一个或多个值。例如,LPUSH mylist "world" ,在列表mylist的左侧插入元素world 。
- RPUSH:从列表的右侧插入一个或多个值。如RPUSH mylist "hello" ,在列表mylist的右侧插入元素hello 。
- LPOP:从列表的左侧弹出一个值。LPOP mylist ,会返回world ,此时列表中只剩下hello 。
- SADD:用于向集合中添加一个或多个成员。例如,SADD myset "apple" ,向集合myset中添加元素apple 。
- SMEMBERS:获取集合中的所有成员。SMEMBERS myset ,将返回apple 。
- SISMEMBER:判断一个元素是否是集合的成员。如SISMEMBER myset "apple" ,如果是则返回 1,否则返回 0。
- ZADD:向有序集合中添加成员及其分数。例如,ZADD myzset 10 "item1" ,向有序集合myzset中添加元素item1 ,分数为 10 。
- ZRANGE:根据索引范围获取有序集合中的成员。ZRANGE myzset 0 -1 ,获取有序集合myzset中的所有元素,按分数从小到大排序(-1表示最后一个元素)。
- ZRANK:获取元素在有序集合中的排名。ZRANK myzset "item1" ,返回item1在有序集合myzset中的排名 。
(二)数据结构操作
Redis 支持多种数据结构,不同数据结构的操作方法和应用场景各有不同:
- 字符串(String):这是最基本的数据结构,操作方法简单直观。除了前面提到的SET、GET、INCR等命令,还可以使用APPEND命令向字符串追加内容,STRLEN命令获取字符串长度等。例如,在缓存用户登录状态时,可将用户 ID 作为键,登录状态(如logged_in或logged_out)作为值存储为字符串;在实现计数器时,利用INCR命令对表示计数的键进行原子性自增操作 。
- 哈希(Hash):适用于存储对象。通过HSET、HGET等命令操作字段和值。在存储用户信息时,以用户 ID 为键,将用户名、邮箱、手机号码等作为字段存储在哈希中,方便对用户信息进行统一管理和修改。例如,在电商系统中,以商品 ID 为键,商品的名称、价格、库存等属性作为字段存储在哈希中,便于对商品信息进行管理和更新 。
- 列表(List):基于双向链表实现,支持在两端进行插入和删除操作。常用命令有LPUSH、RPUSH、LPOP、RPOP等。在实现消息队列时,生产者使用RPUSH命令将消息添加到列表右侧,消费者使用LPOP命令从列表左侧获取消息,实现消息的先进先出;在实现任务队列时,也可利用列表的特性,将任务依次添加到队列中,后台处理程序按顺序取出任务进行处理 。
- 集合(Set):是无序且唯一的元素集合,支持集合运算。常用命令有SADD、SREM、SMEMBERS、SINTER(交集)、SUNION(并集)、SDIFF(差集)等。在统计网站独立访客数量时,将每个访客 ID 添加到集合中,利用集合的唯一性实现去重;在社交网络中,通过集合的交集操作可以找出两个用户的共同好友,通过并集操作可以找出所有好友的集合,通过差集操作可以找出某个用户独有的好友 。
- 有序集合(Sorted Set):每个元素关联一个分数,根据分数排序。常用命令有ZADD、ZRANGE、ZREVRANGE(按分数从大到小排序)、ZINCRBY(增加元素的分数)等。在游戏中,根据玩家得分排名,将玩家 ID 作为元素,得分作为分数存储在有序集合中,通过ZRANGE命令获取排名靠前的玩家;在电商系统中,根据商品销量排名,将商品 ID 作为元素,销量作为分数存储在有序集合中,方便展示热门商品排行榜 。
(三)事务处理
Redis 事务是一组命令的集合,这些命令会被顺序化并串行执行,保证在执行期间不会被其他客户端的命令插入 。
- 概念:Redis 事务通过MULTI、EXEC、DISCARD和WATCH四个命令来实现。MULTI用于标记事务开始,之后的命令会被放入队列,而不是立即执行;EXEC用于执行事务队列中的所有命令;DISCARD用于取消事务,放弃执行事务块内的所有命令;WATCH用于在事务开始前监视一个或多个键,若在EXEC执行前,被监视的键被其他客户端修改,则整个事务会失败(EXEC返回nil) 。
- 使用方法:以下是一个简单的 Redis 事务示例,假设我们要对两个库存键进行操作,确保它们的扣减操作是原子性的:
127.0.0.1:6379> SET a:stock 100 # 初始化库存a为100OK127.0.0.1:6379> SET b:stock 200 # 初始化库存b为200OK127.0.0.1:6379> MULTI # 开启事务OK127.0.0.1:6379> DECR a:stock # 将a:stock减1QUEUED127.0.0.1:6379> DECR b:stock # 将b:stock减1QUEUED127.0.0.1:6379> EXEC # 执行事务1) (integer) 992) (integer) 199
- 注意事项:Redis 事务有一些特性和注意点需要关注。首先,Redis 事务没有隔离级别概念,事务中的命令在执行前不会被实际执行,也就不会有 “事务内的查询看到事务里的更新” 这种情况;其次,Redis 事务不保证原子性,如果事务中某条命令执行失败,后续命令仍然会执行,且没有回滚机制;此外,WATCH命令实现的乐观锁机制依赖于被监视键的变化情况,如果业务逻辑复杂,仅靠WATCH可能无法完全保证数据的一致性 。在实际应用中,对于需要严格原子性和回滚机制的场景,可能需要结合其他技术或自行实现补偿逻辑 。例如,在电商库存扣减场景中,如果扣减库存失败,需要手动进行库存回滚操作,或者记录操作日志以便后续处理 。
六、Redis 在项目中的应用案例
(一)电商项目中的应用
在电商项目中,Redis 起着至关重要的作用,涵盖多个核心业务场景。
在商品缓存方面,电商平台存在大量商品信息,用户频繁访问商品详情页。将商品信息,如名称、价格、描述、图片等缓存至 Redis,能大幅提升数据读取速度。在高并发的购物节期间,如双十一,大量用户同时请求商品详情。若从传统数据库读取,可能因 I/O 瓶颈导致响应缓慢甚至系统崩溃。而 Redis 的内存存储特性,可实现快速响应,提升用户购物体验。以某知名电商平台为例,采用 Redis 缓存商品信息后,商品详情页加载速度提升了 80%,大大降低了数据库压力 。
库存管理上,电商平台库存数据实时变化,高并发场景下对库存操作的原子性和高效性要求极高。Redis 的原子操作命令,如 INCRBY、DECRBY,可轻松实现库存的增减操作。在秒杀活动中,利用 Redis 结合 Lua 脚本来保证库存扣减的原子性,防止超卖现象。某电商平台在一次大型秒杀活动中,通过 Redis 进行库存管理,成功处理了每秒上万次的库存扣减请求,确保了库存数据的准确性 。
用户会话管理中,在分布式电商系统里,为实现用户的单点登录和会话保持,可将用户会话信息,如登录状态、用户 ID、购物车信息等存储在 Redis 中。用户在不同页面或服务间切换时,能快速验证用户身份和获取会话信息。当用户将商品加入购物车时,购物车数据实时存储到 Redis,用户下次访问时可快速加载购物车内容,提升购物的连贯性和便捷性 。
(二)社交平台中的应用
在社交平台中,Redis 同样发挥着关键作用,助力实现多个核心社交功能。
点赞功能的实现上,社交平台中点赞操作频繁,实时性要求高。使用 Redis 的 INCR 命令可轻松实现点赞数的原子性递增。当用户点赞一篇帖子时,执行 INCR 操作,快速增加帖子的点赞数。同时,利用 Redis 的集合数据结构,可记录点赞用户 ID,方便查询某用户是否点赞过某帖子,以及获取点赞用户列表。某社交平台通过 Redis 实现点赞功能后,点赞响应时间从原来的几百毫秒缩短至几毫秒,极大提升了用户交互体验 。
关注功能的实现,用户关注关系的数据量庞大且读写频繁,Redis 的集合数据结构是实现关注功能的理想选择。使用两个集合分别存储用户关注的人和关注该用户的人,通过集合操作实现关注、取关、查询共同关注等功能。当用户 A 关注用户 B 时,将用户 B 的 ID 添加到用户 A 的关注集合中,同时将用户 A 的 ID 添加到用户 B 的粉丝集合中。查询用户 A 和用户 B 的共同关注时,通过对两个集合进行交集操作即可快速得出结果 。
消息推送的实现,社交平台需要实时推送消息给用户,如关注提醒、评论回复提醒等。Redis 的发布 / 订阅模式能很好地满足这一需求。当用户 A 关注用户 B 时,发布一条关注消息到特定频道,用户 B 作为订阅者可实时接收到该消息。通过结合消息队列和持久化机制,可确保消息不丢失,即使在高并发情况下也能稳定运行。某社交平台使用 Redis 实现消息推送后,消息送达率达到了 99% 以上,有效提升了用户互动性 。
七、Redis 的性能优化与高可用方案
(一)性能优化技巧
在使用 Redis 时,合理的性能优化至关重要。首先,要根据业务需求选择合适的数据结构,不同的数据结构在内存占用和操作效率上有很大差异。例如,在存储用户信息时,若需要频繁根据用户 ID 查询用户的多个属性,使用哈希结构比使用字符串结构更高效,因为哈希结构可以通过字段快速定位值,减少不必要的内存开销和查询时间 。
在键值设计方面,尽量使用简短且有意义的键名,避免过长或复杂的命名。过长的键名不仅会占用更多的内存空间,还可能增加网络传输的开销,影响 Redis 的读写性能。对于值的设计,要尽量减少不必要的冗余数据,确保存储的数据紧凑且高效 。
批量操作和管道技术是提升 Redis 性能的有效手段。Redis 提供了 MGET、MSET 等批量操作命令,通过批量操作,可以减少网络开销,提高数据读写效率。例如,当需要获取多个键的值时,使用 MGET 命令一次性获取,比多次使用 GET 命令要快得多。管道技术允许客户端一次性发送多个命令到 Redis 服务器,服务器在处理完所有命令后一次性返回结果。这样可以减少客户端和服务器之间的往返时间,大幅提升性能,尤其在需要执行大量命令的场景下,管道技术的优势更为明显 。
此外,使用 Lua 脚本也能提升性能。Lua 脚本可以在 Redis 服务器端原子性地执行多个操作,减少网络开销和锁竞争。可以将一些逻辑封装成 Lua 脚本,提高执行效率和保证原子性。例如,在实现分布式锁时,使用 Lua 脚本可以确保加锁和解锁操作的原子性,避免因并发操作导致的锁失效问题 。
(二)主从复制
Redis 主从复制是将一个 Redis 服务器(Master 主节点)的数据复制到其他 Redis 服务器(Slave 从节点)的过程,数据的复制是单向的,只能由主节点到从节点 。
主从复制的原理如下:当从节点启动并成功连接到主节点后,从节点会向主节点发送一个 PSYNC 命令,请求进行数据同步。主节点在接收到 PSYNC 命令后,会执行一个后台的存盘进程(即 RDB 持久化过程),生成一个数据快照文件(.rdb 文件)。同时,主节点会缓存这期间接收到的所有写命令,以便后续发送给从节点。当主节点的快照生成完毕后,它会将这个快照文件以及缓存的所有写命令发送给从节点。从节点接收到主节点发送的快照文件和写命令后,会先将快照文件加载到本地内存中,然后执行这些写命令,以确保与主节点的数据保持一致 。在初始化同步完成后,主节点每次接收到写命令时,都会将这些命令发送给从节点,从而保持主从节点之间的数据一致性。这种同步是持续进行的,确保从节点始终拥有主节点的最新数据 。
在配置主从复制时,主节点通常只需进行一些基本配置,如启用主节点(daemonize yes)、设置监听 IP 和端口、设置认证密码(可选)、开启 AOF 持久化(可选,默认 RDB 持久化)等。从节点则需要在配置文件中设置启用从节点(daemonize yes)、设置监听 IP 和端口、设置认证密码(与主节点一致),并通过 replicaof 命令设置主节点的地址和端口 。例如,在从节点的配置文件中添加 “replicaof 192.168.1.100 6379”,表示该从节点复制 IP 为 192.168.1.100、端口为 6379 的主节点的数据 。配置完成后,分别启动主节点和从节点,通过查看从节点的状态(使用 redis-cli -h < 从节点 IP> -p < 从节点端口 > info replication 命令),若看到输出中有 role:slave,且 master_host 和 master_port 显示正确的主节点地址和端口,说明主从复制已经配置成功 。
主从复制在实际应用中具有重要作用。它可以实现数据的冗余备份,由于从节点是主节点的副本,主节点数据的备份可以在从节点上实现,提高了数据的安全性。通过将数据复制到多个从节点,即使主节点发生故障,从节点可替代主节点提供服务,从而保障系统的高可用性 。主从复制还能实现读写分离,主节点负责处理写入操作,从节点负责处理读操作,从而分担主节点的负载,提高系统的整体性能,尤其适用于读多写少的业务场景 。
(三)哨兵模式
Redis Sentinel(哨兵模式)是 Redis 提供的一种高可用性解决方案,主要用于监控 Redis 主从节点的状态,并在检测到故障时自动进行故障转移 。
哨兵模式的工作原理较为复杂,它由多个组件协同工作来实现高可用性。哨兵节点负责监控主从节点的健康状态,通过定期向 Redis 主节点和从节点发送 PING 请求,以检查它们的健康状态。如果某个节点在指定时间内没有响应,哨兵会将其标记为 “主观下线”(Subjectively Down,SDOWN) 。当哨兵检测到主节点不可用(超时或无法连接),且在一定时间内无法恢复,它会进入一个故障检测阶段。在这个阶段,哨兵集群会对该节点进行投票,当同意主节点进入主观下线的哨兵数量大于等于配置文件中设定的 quorum 值(法定人数,用于判定客观下线的哨兵数量要求),则主节点会被标记为 “客观下线”(Objectively Down,ODOWN) 。一旦主节点被标记为客观下线,哨兵集群会发起选举,选出一个哨兵来执行故障转移操作。这个选举过程使用的是多数投票机制,确保决策的正确性。选举出的哨兵会选择一个健康的从节点,并将其提升为新的主节点 。选择从节点的规则如下:优先选择复制偏移量最大的从节点(即数据最完整);如果多个从节点的复制偏移量相同,优先选择优先级最高的从节点(通过 slave-priority 配置);如果优先级也相同,优先选择运行时间最长的从节点 。所有的哨兵会更新配置,指向新的主节点,同时,所有从节点会将新的主节点作为它们的主节点进行数据同步 。哨兵还会通过配置提供者接口通知客户端,告知新的主节点地址,客户端可以根据这些信息动态地调整连接 。
以配置 1 主 2 从 3 哨兵的 Redis 服务器为例,假设主服务器 IP 为 192.168.1.100,端口为 6379;从服务器 1 IP 为 192.168.1.101,端口为 6380;从服务器 2 IP 为 192.168.1.102,端口为 6381;哨兵 1 IP 为 192.168.1.103,端口为 26379;哨兵 2 IP 为 192.168.1.104,端口为 26380;哨兵 3 IP 为 192.168.1.105,端口为 26381 。首先配置 Redis 的主、从服务器,在主服务器的 redis.conf 文件中,设置 bind 0.0.0.0(使得 Redis 服务器可以跨网络访问)、protected-mode no(关闭保护模式)、requirepass "123456"(设置密码) 。在从服务器的 redis.conf 文件中,除了上述配置外,还需添加 slaveof 192.168.1.100 6379(指定主服务器)和 masterauth 123456(主服务器密码) 。配置 3 个哨兵,每个哨兵的配置都是一样的,在 Redis 源码目录下找到 sentinel.conf 文件,copy 一份进行修改 。例如,禁止保护模式(protected-mode no)、设置端口(port 26379)、以守护进程模式运行(daemonize yes)、指定 pid 文件路径(pidfile /var/run/redis-sentinel-26379.pid)、指定日志文件路径(logfile 26379.log) 。配置监听的主服务器,如 sentinel monitor mymaster 192.168.1.100 6379 2(这里 sentinel monitor 代表监控,mymaster 代表服务器的名称,可以自定义,192.168.1.100 代表监控的主服务器,6379 代表端口,2 代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行 failover 操作) 。设置服务密码,如 sentinel auth-pass mymaster 123456 。配置完成后,首先启动主的 Redis 服务进程,然后启动从机的服务进程,最后启动 3 个哨兵的服务进程 。
哨兵模式的优点显著,它能提供高可用性,当主节点故障时,哨兵会自动进行故障转移,确保系统的持续运行;实现自动故障转移,减少了系统停机时间,提高了业务的连续性;支持多节点,增加哨兵节点可以提高系统的容错能力,增强了系统的稳定性 。然而,哨兵模式也存在一些缺点,配置相对复杂,需要配置多个哨兵实例,并确保其正确工作,对运维人员的技术要求较高;在故障转移过程中可能会产生短暂的延迟,导致短暂不可用和数据不一致,在对数据一致性要求极高的场景下,可能需要采取额外的措施来保证数据的完整性 。
(四)集群部署
Redis 集群是一种分布式的 Redis 解决方案,采用无中心分布式架构,每个节点地位平等,都保存完整的集群状态信息,用于解决单机模式下的内存容量上限、计算能力瓶颈和单点故障风险等问题 。
Redis 集群的数据分片采用哈希槽(Hash Slot)机制,集群固定使用 16384 (2^14) 个哈希槽位,每个主节点负责一部分槽位,数据根据键的哈希值映射到对应槽位上 。当客户端要操作一个键时,Redis 通过以下算法确定键属于哪个槽位:首先检查键中是否有 {} 标签,若有则提取哈希标签内的内容作为计算依据,计算 CRC16 值后与 16383 进行按位与操作(即取模 16384),得到的结果就是键对应的哈希槽位 。例如,对于键 user:{123}:profile,哈希标签为 {123},计算 {123} 的 CRC16 值后取模 16384,即可确定其所在的哈希槽位 。哈希标签功能允许将不同的键强制映射到同一个槽位,对于多键操作(如事务、Lua 脚本)至关重要,因为 Redis 集群的多键操作要求所有相关键必须位于同一个槽位,否则会返回 CROSSSLOT 错误 。
在节点通信方面,Redis 集群使用 Gossip 协议进行节点间通信,这是一种去中心化的协议,具有容错性强、最终一致性等特点 。Gossip 消息包含节点 ID、IP 地址和端口、节点角色标识(主 / 从)、槽位分配信息(使用 16384 位的位图压缩表示)、节点状态标记(如 PFAIL/FAIL)、配置纪元(config epoch,集群全局版本号)、选举纪元(election epoch,选举轮次标识)等关键信息 。Gossip 主要传递 MEET(用于引入新节点到集群,包含新节点的地址信息)、PING(周期性发送,默认每秒发送 1 次,随机选择几个节点,大规模集群自动调整频率)、PONG(响应 MEET/PING,或每隔一段时间主动广播状态)、FAIL(通知集群某节点已经失效)、PUBLISH(向集群广播消息)等类型的消息 。每个节点维护一个集群状态表,通过频繁交换 PING/PONG 消息不断更新各节点状态 。
故障检测和自动故障转移是 Redis 集群的重要特性。当节点 A 在规定时间内(cluster-node-timeout)没有收到节点 B 的 PONG 响应,且确认不是因从节点复制延迟导致,节点 A 会将 B 标记为主观下线(PFAIL) 。当超过半数的主节点(从节点不参与投票)都认为某节点主观下线时,会将其标记为客观下线(FAIL),并广播 FAIL 消息通知整个集群 。当主节点被标记为客观下线后,从节点发现自己的主节点进入客观下线状态,会计算自己的选举优先级(根据复制偏移量和 replica-priority 配置),等待随机时间后发起选举(偏移量越大,延迟越小) 。获得多数主节点投票的从节点成为新主节点,新主节点更新集群状态,接管原主节点的槽位,其他从节点开始复制新主节点的数据 。
在部署 Redis 集群时,假设要部署一个包含 3 个主节点和 3 个从节点的集群。首先,准备 6 台服务器,分别安装 Redis,并配置不同的端口,如主节点 1 端口为 7000,主节点 2 端口为 7001,主节点 3 端口为 7002,从节点 1 端口为 7003,从节点 2 端口为 7004,从节点 3 端口为 7005 。在每个 Redis 节点的配置文件中,设置 cluster-enabled yes(启用集群模式)、cluster-config-file nodes-7000.conf(指定集群配置文件,不同端口对应不同的配置文件名)、cluster-node-timeout 5000(设置节点超时时间为 5000 毫秒)、appendonly yes(开启 AOF 持久化) 。配置完成后,使用 redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 --cluster-replicas 1 命令创建集群,其中 --cluster-replicas 1 表示每个主节点对应 1 个从节点 。客户端可以使用 Jedis 等库连接和操作 Redis 集群,实现数据的分布式存储和管理 。例如,在 Java 中使用 Jedis 连接 Redis 集群的代码如下:
import redis.clients.jedis.HostAndPort;import redis.clients.jedis.JedisCluster;import java.util.HashSet;import java.util.Set;public class RedisClusterExample {public static void main(String[] args) {// 定义Redis集群节点Set<HostAndPort> jedisClusterNodes = new HashSet<>();jedisClusterNodes.add(new HostAndPort("127.0.0.1", 7000));jedisClusterNodes.add(new HostAndPort("127.0.0.1", 7001));jedisClusterNodes.add(new HostAndPort("127.0.0.1", 7002));jedisClusterNodes.add(new HostAndPort("127.0.0.1", 7003));jedisClusterNodes.add(new HostAndPort("127.0.0.1", 7004));jedisClusterNodes.add(new HostAndPort("127.0.0.1", 7005));// 创建JedisCluster对象try (JedisCluster jedisCluster = new JedisCluster(jedisClusterNodes)) {// 执行操作,例如设置键值对jedisCluster.set("key1", "value1");// 获取值String value = jedisCluster.get("key1");System.out.println("Value of key1: " + value);} catch (Exception e) {e.printStackTrace();}}}Redis 集群在应对高并发和海量数据存储方面具有显著优势。它可以通过水平扩展节点来增加存储容量和处理能力,将数据分散到多个节点上,避免了单个节点的性能瓶颈 。在高并发场景下,集群中的多个节点可以同时处理请求,提高了系统的并发处理能力,确保系统在大量请求下仍能稳定运行 。
八、总结与展望
Redis 作为一款高性能的内存数据结构存储系统,以其卓越的性能、丰富的数据结构和广泛的应用场景,在现代软件开发中占据了举足轻重的地位。从电商到社交平台,从缓存到分布式锁,Redis 的身影无处不在,为各种复杂的业务场景提供了高效、可靠的解决方案。
在未来,随着大数据、人工智能、物联网等技术的飞速发展,数据量将持续爆炸式增长,对数据处理的实时性和高效性要求也将越来越高。Redis 有望在这些新兴领域发挥更大的作用,为数据的存储、处理和分析提供强大的支持。同时,Redis 也将不断演进,持续优化性能,增强分布式系统和高可用性功能,以满足不断变化的业务需求。
对于开发者而言,掌握 Redis 的使用和优化技巧,将为我们的技术栈增添强大的助力,帮助我们在面对复杂的技术挑战时,能够游刃有余地构建出高性能、高可用的应用系统。让我们一起期待 Redis 在未来的技术浪潮中创造更多的可能!